
Parallelism Models
There are three modes of parallelism shown below:
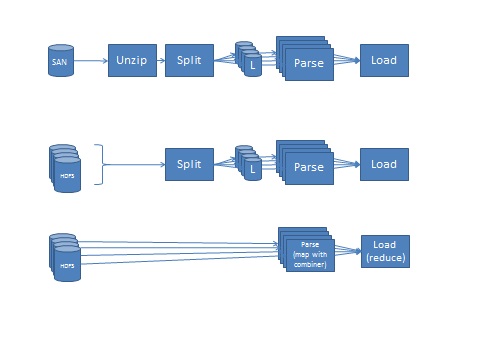
- VDMETL on Regular Unix
- The VDMETL framework reads the files from local storage or more likely a SAN, unzips them serially, then splits them into an appropriate number of fragments which in turn parses in parallel. The vast majority of resource consumption is in parsing the files - 95%-96% from tests on AIX P7 servers. The next biggest cost is the unzip step, which is paid serially. If the file is split in 10 fragments, then the 5% cost of unzipping effectively occupies about 30% on the time-line because the 10 streams are processed in parallel (we ignore the loader for this discussion as it is a common denominator.) Of course if multiple channels are processed at the same time, then this adds an additional dimension of parallelism that is not shown in the diagrams, but effectively helps utilize more and more of the CPUs
- HDFS Piping to VDMETL on Regular Unix
- HDFS may provide a parallel organization of the file itself if the file is very large. Of course, the file is put back into a single stream to feed it to VDM. It is possible to delegate the unzip function to the HDFS in a way that it can be done in parallel before assembling the stream, however this requires compression algorithms that allow splitting. This will reduce or practically eliminate the serial cost of decompression, and the VDM will receive the stream uncompressed. The cost of ingesting the file to HDFS is higher than for a local file system or SAN, this cost can be paid at non critical time outside the tight ETL processing window. Consequently by simply using the HDFS and piping directly to the VDM we can get some performance benefit, in addition to cost and redundancy advantages
- HDFS with Map-Reduce Parsers
- By using the parsers as mappers, we avoid the funneling into a single pipe and the re-splitting of the data. This can be done using Hadoop Stream API using existing VDM parsers, or generating Hadoop-specific parsers in Java or other languages. Given that the lion's share of the resource usage is with parsing, which is parallel in both VDM and Hadoop, this may improve the run-time of the end-to-end process in a limited way, depending on the configuration. If the parsers are written in Java, or they carry additional overhead caused by additional functionality, such as UTF-8 support and AVRO serialization, they may run slower regardless of the language. So the decision should be based on the additional value that Hadoop-enabled parsers can provide. Such value includes:
- Multilingual support - second level UTF-8 compliance
- Standard schema and serialization protocol by using AVRO
- Hadoop's distributed run-time automation
- Fully enabling Hadoop-VDMETL integration
VDM Access:
